


Allegheny Thesis Work
Approximate Algorithmic Image Matching to Reduce Online Storage Overhead of User Submitted Images
Project scope
The Allegheny College Department of Computer Science set the following requirements for the thesis project:
- Choose a topic that can be researched and evaluated in a one year time frame.
- Schedule and attend weekly meetings with your thesis adviser.
- Complete and have a written proposal approved by the first reader of your choosing.
- Create a presentation and defend your thesis proposal showing its feasibility and benefit as a thesis topic.
- Submit a completed written thesis document to your first and second readers which has been formatted according to the department thesis guide. This will initially be submitted in an unbound form and will later undergo final revisions and approval before binding and submitting a final copy for archiving.
- Create a presentation and defend the results of your thesis to the first and second readers.
* The original senior thesis course syllabus and guidelines have been made available for download at the bottom of this webpage.
Note: Upon completion of the thesis, I was chosen as one of two seniors from the department to present my research at the college-wide senior thesis celebration. In order to do this, I created a poster that outlined the topic, research, and the results as an additional deliverable that isn't typically required of seniors. This can be downloaded from the senior thesis project page along with several other documents and additional information.
Background
⇒ Purpose
Current systems allow for duplicate data to be uploaded to the server by multiple users, requiring large amounts of storage space. The research completed targets the issue of storing user submitted image data while reducing storage overhead through a series of algorithms and analysis methods.
⇒ Example
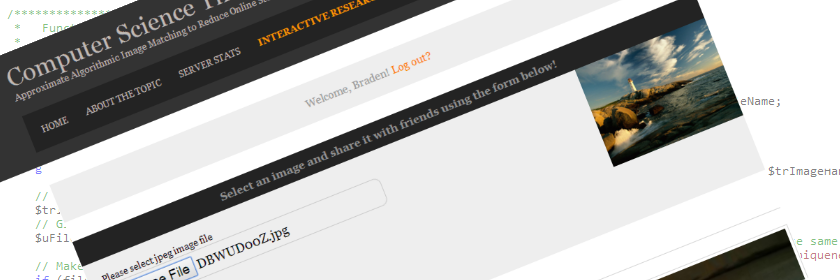
Websites such as imgur, Photobucket, as well as many others allow users to upload and share images free of cost. User A wishes to share an image with friends and uploads said image to the server and is provided a link that the public can access the image from. User B also wishes to share the exact same image (possibly a different resolution) and uploads it to the server. Both users have added identical, or near identical information to the server and have caused redundancy.
⇒ Use of the system
As with the earlier example, user A wants to share an image and uploads it to the photo sharing website. The image is processed, determined to be unique, and is subsequently added to the server. User B also wishes to share the same image (possibly a different resolution) and proceeds to upload it to the server, it is processed and determined to be a duplicate of an image already on the server.
If the new image is lower resolution or the same resolution as the existing one, the site shows the user the most probable match and displays the higher/same resolution image and the one they wish to upload. If the user determines it is the same image, the new image will be discarded and a link will be generated for the existing image. If the new image is a higher resolution, and the user states it is the same, the new image will be uploaded and the old one preserved to keep users from maliciously overwriting a previous share.
⇒ Benefit
By using this system, storage costs are reduced in addition to electrical costs as less server nodes are required to operate to support storage space requirements. In addition, the users receive better service as a higher resolution image alternative may be recommended to the one they wish to share.
Project Results
After completion of the image sharing system, it was evaluated and graded based on several metrics, namely performance, effectiveness (accuracy), and usability. Several image test suites were built and tested on this system that included:
- Small-sized photographic images
- Large-sized photographic images
- Small-sized computer generated graphics (patterns)
- and Large-sized computer generated graphics.
After evaluating the results, it was shown that more than 80% of duplicate images were detected with less than 1% of detections being false positives. It was also determined that larger image sizes directly correspond to higher accuracy in duplicate identification. Surprisingly though, computer generated graphic duplicates were only correctly identified approximately 30% of the time, and more than 20% of duplicates were false positives. This was attributed to a high amount of detail in repetitive black and white images. By using color images, or high resolution images with minimal fine details, the algorithm performed well as mentioned before.
Finally, from a performance standpoint, the system exceeded expectations, completing uploads with minimal additional wait time. These times were small enough that the typical user would not notice, as the fraction of a second variation remained less than those of fluctuating internet speeds. Even the worst case scenario with a large complex file requiring the most analysis, less than a two second wait was observed. In addition, this system maintained complete usability with a minimum required number of two clicks to upload and share a unique image, or three clicks if a duplicate was detected. Overall, this research exceeded expectations and even returned unexpected results opening a path for future research and improvement.
Project Links
- To visit the thesis website please click this link and take a look around. (Note: The function being researched is password protected to ensure continuous integrity of test data and security of the project source.)
- Access to the thesis document itself is available through the research website or by clicking here.
- To view the presentation used in the defense of this thesis, click here!
- This project was honored with the opportunity to present findings to the college, this document may be viewed here.